QuotaGuard Engineering
Articles by QuotaGuard Engineering
Articles by QuotaGuard Engineering
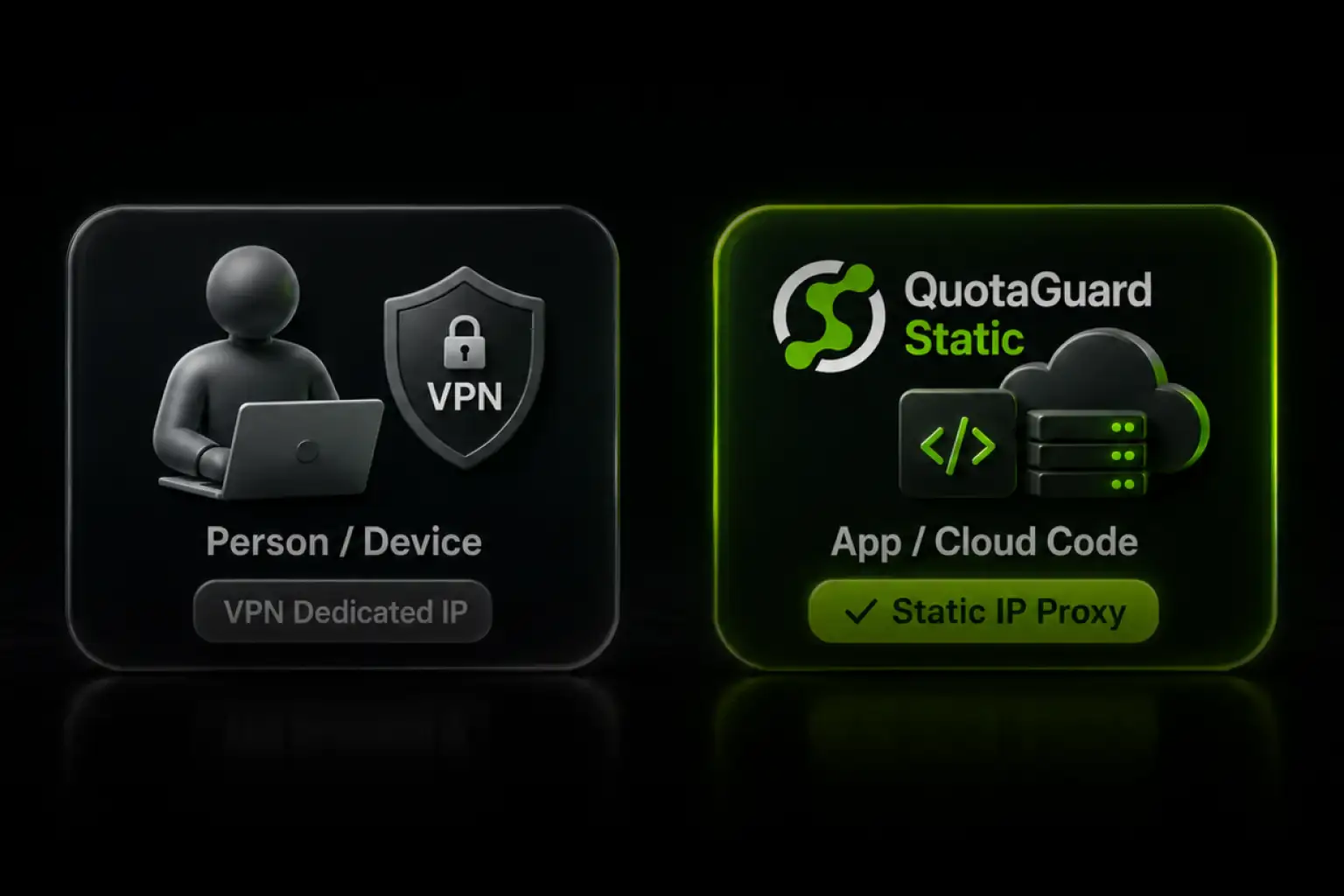
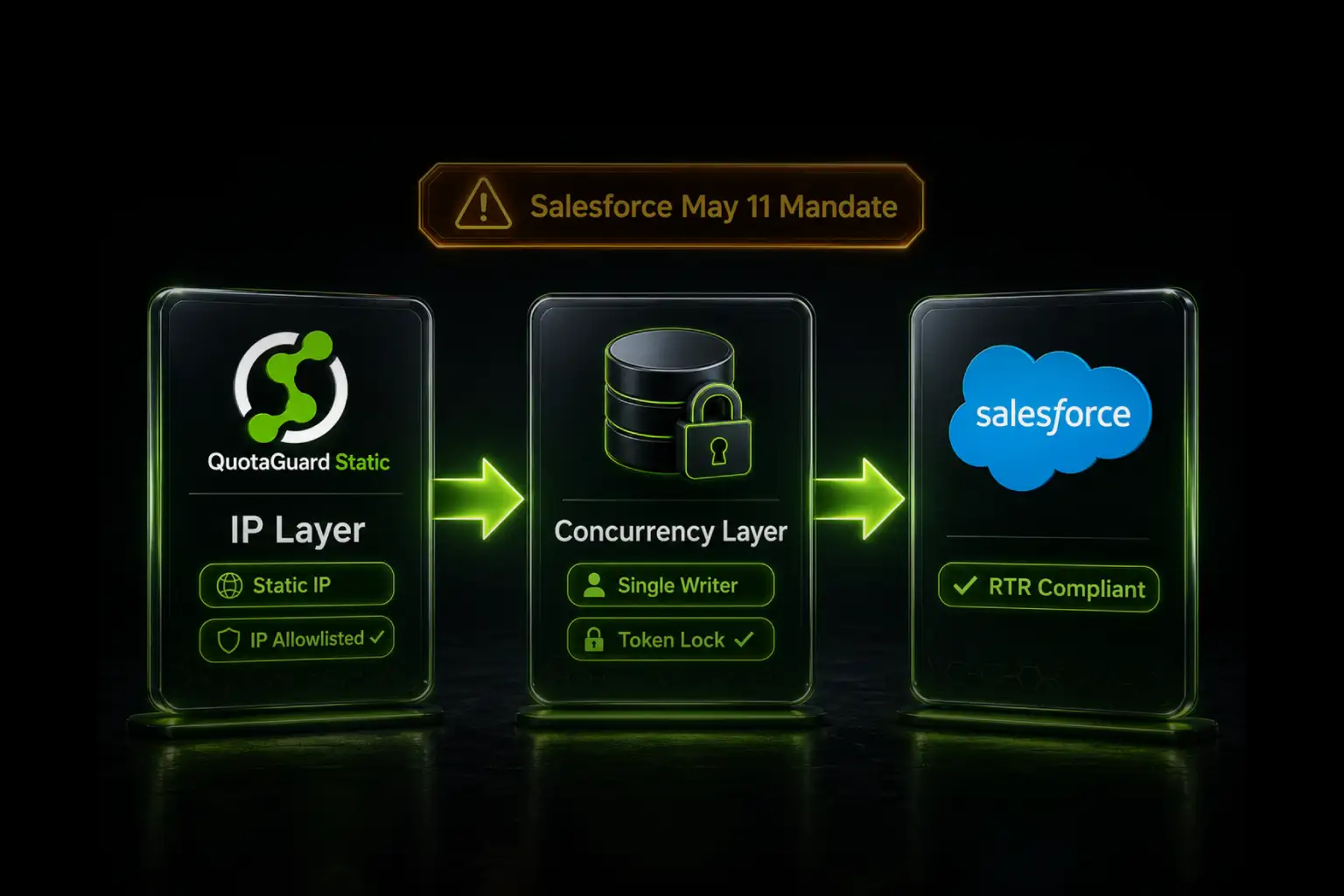
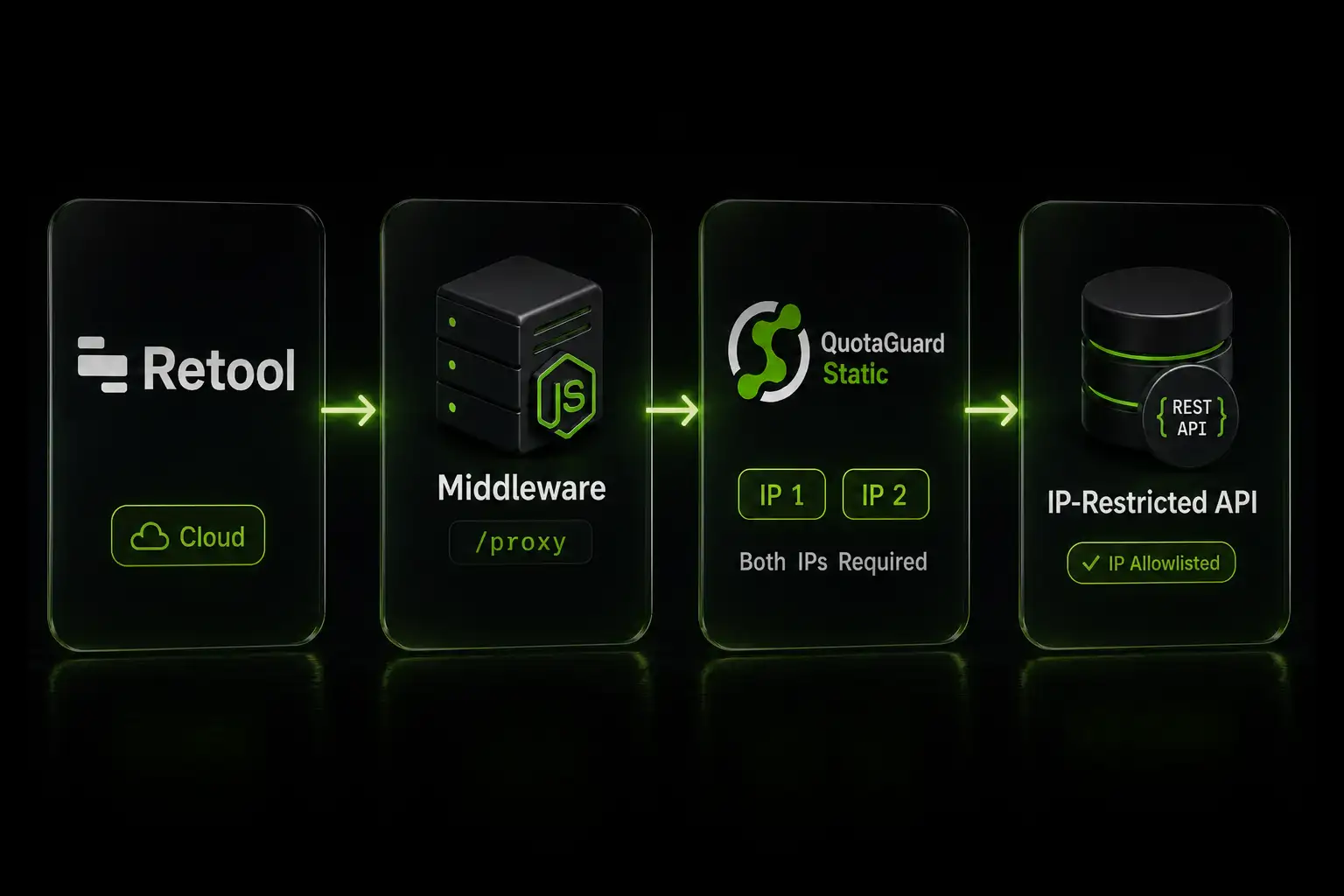
For over a decade, QuotaGuard has provided reliable, high-performance static IP and proxy solutions for cloud environments like Heroku, Kubernetes, and AWS.
Get the fixed identity and security your application needs today.

.webp)
.webp)


.webp)








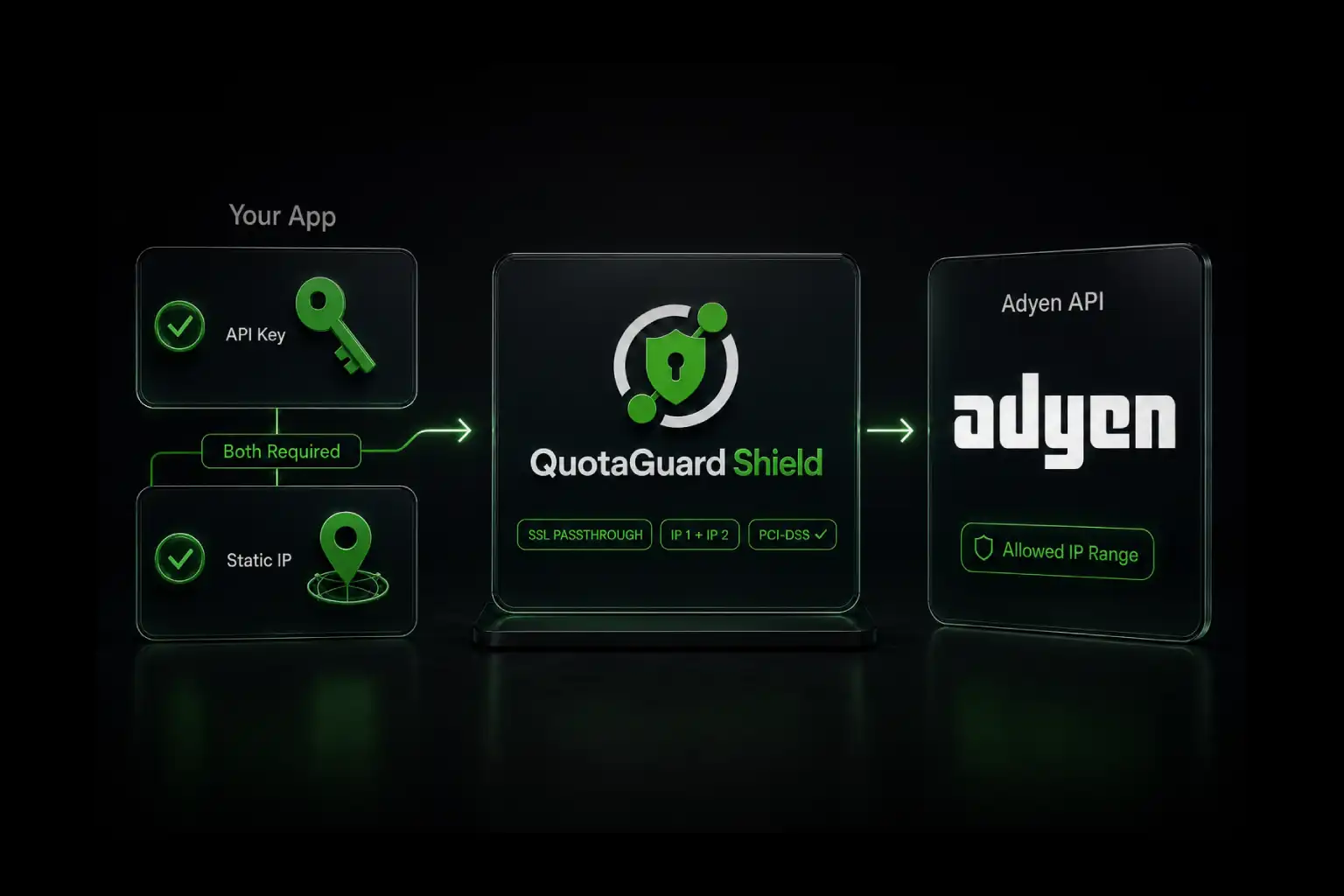


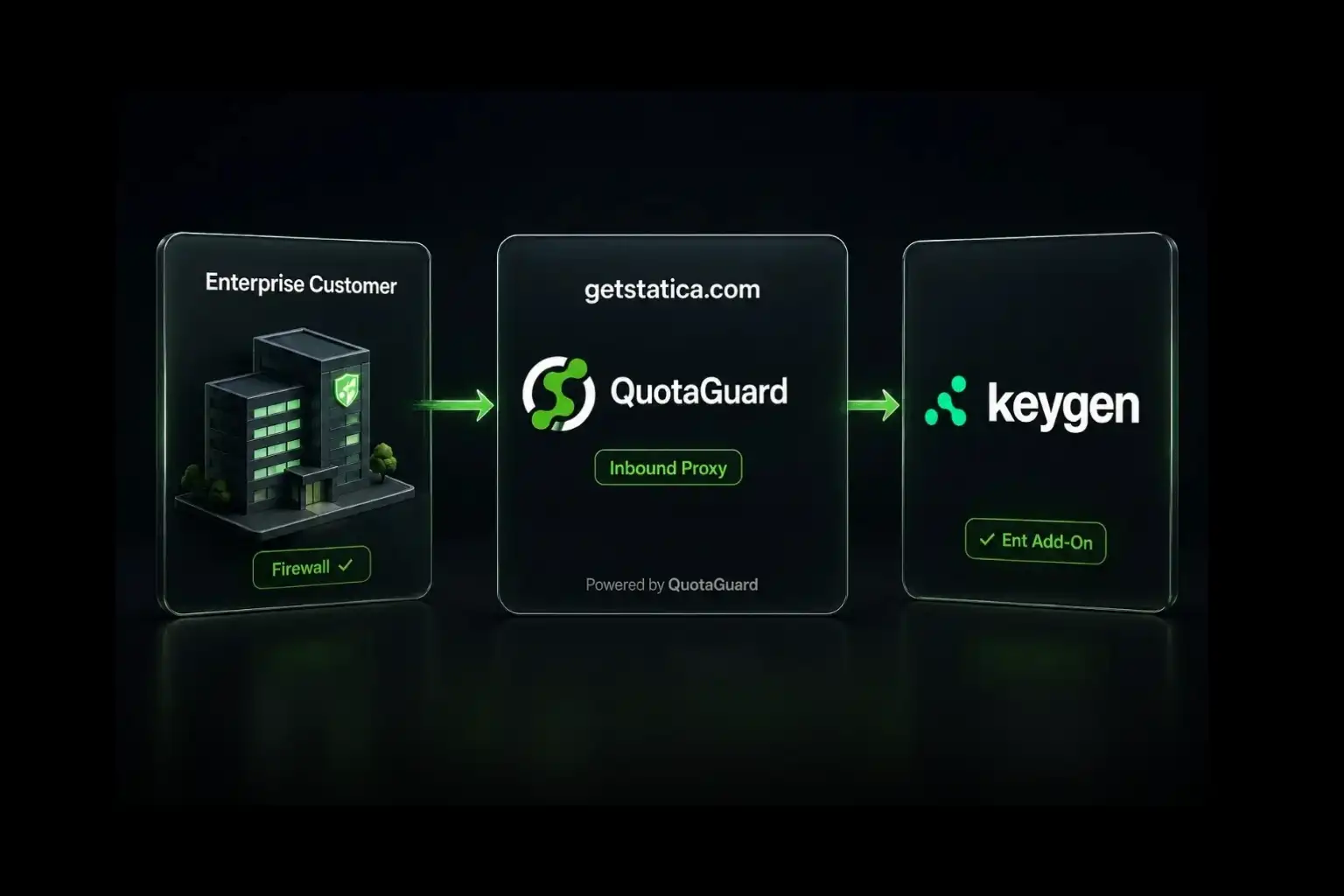


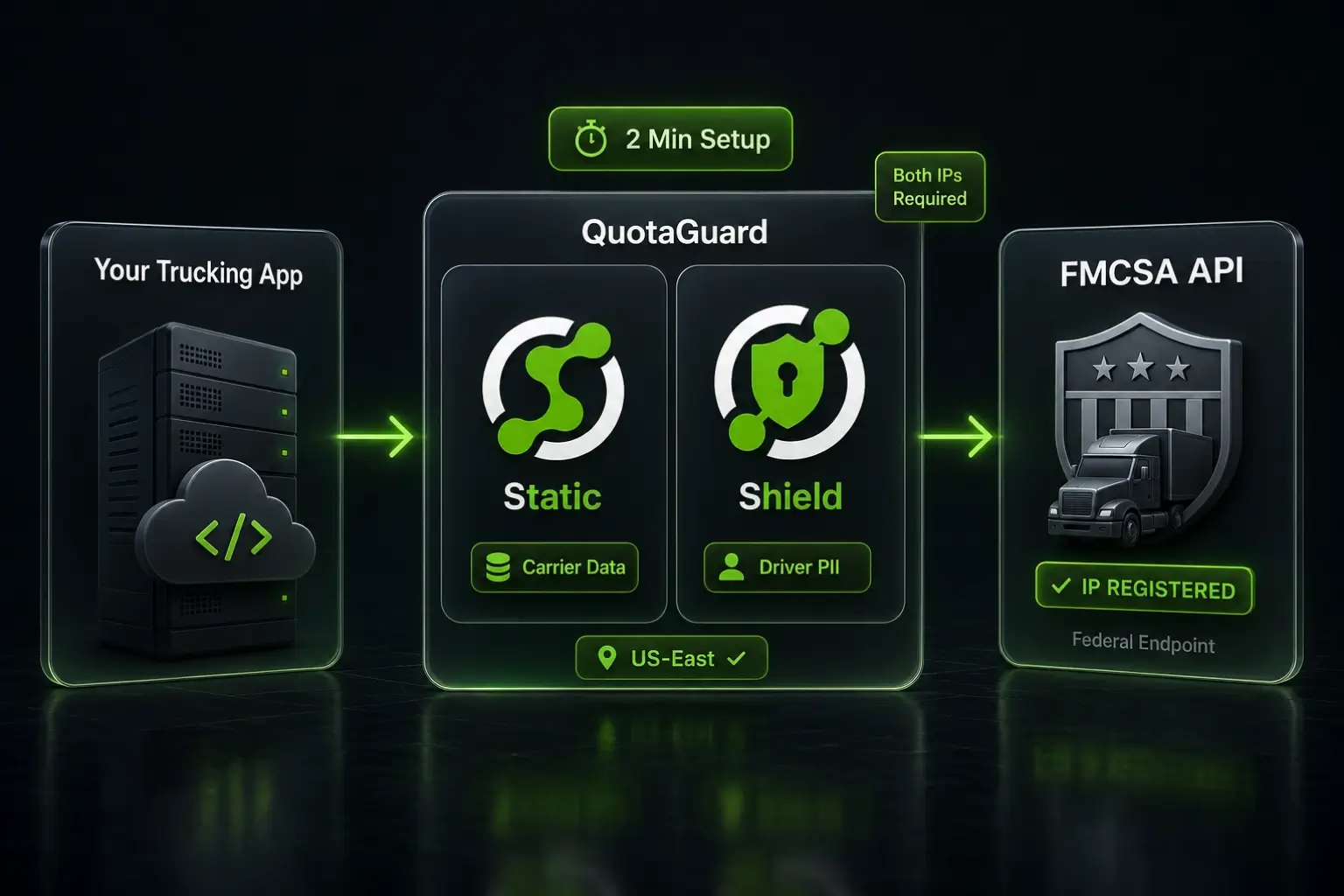






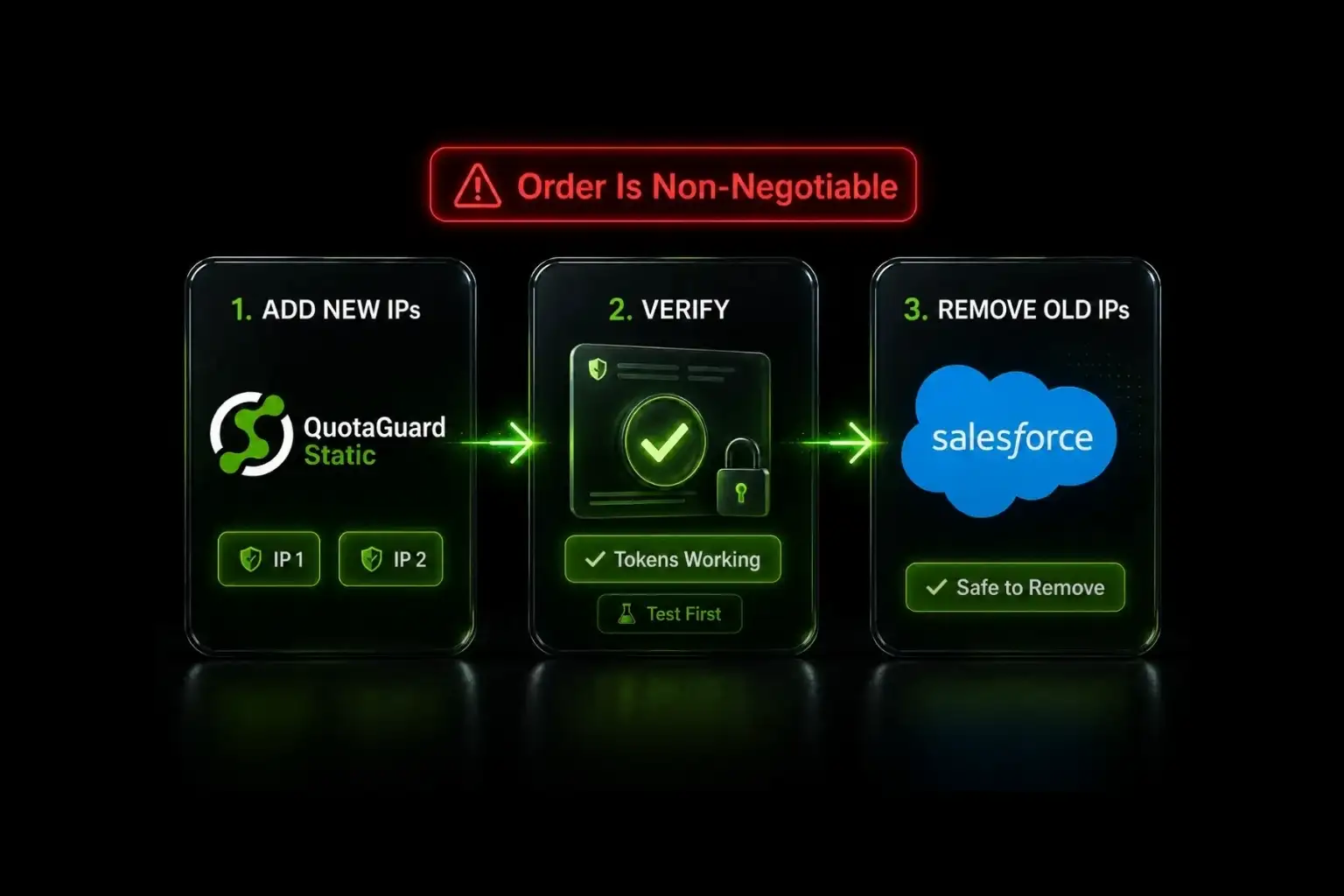
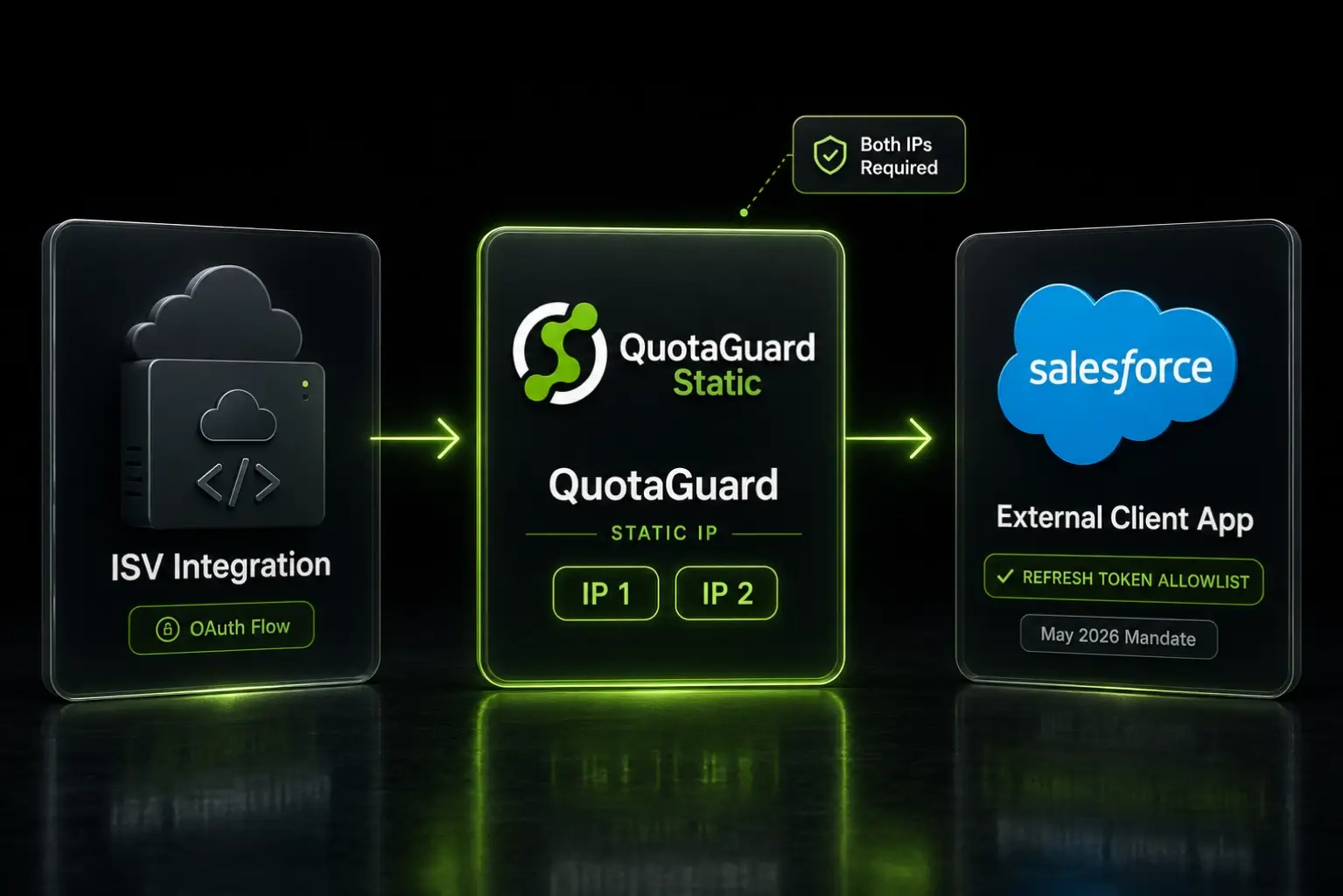
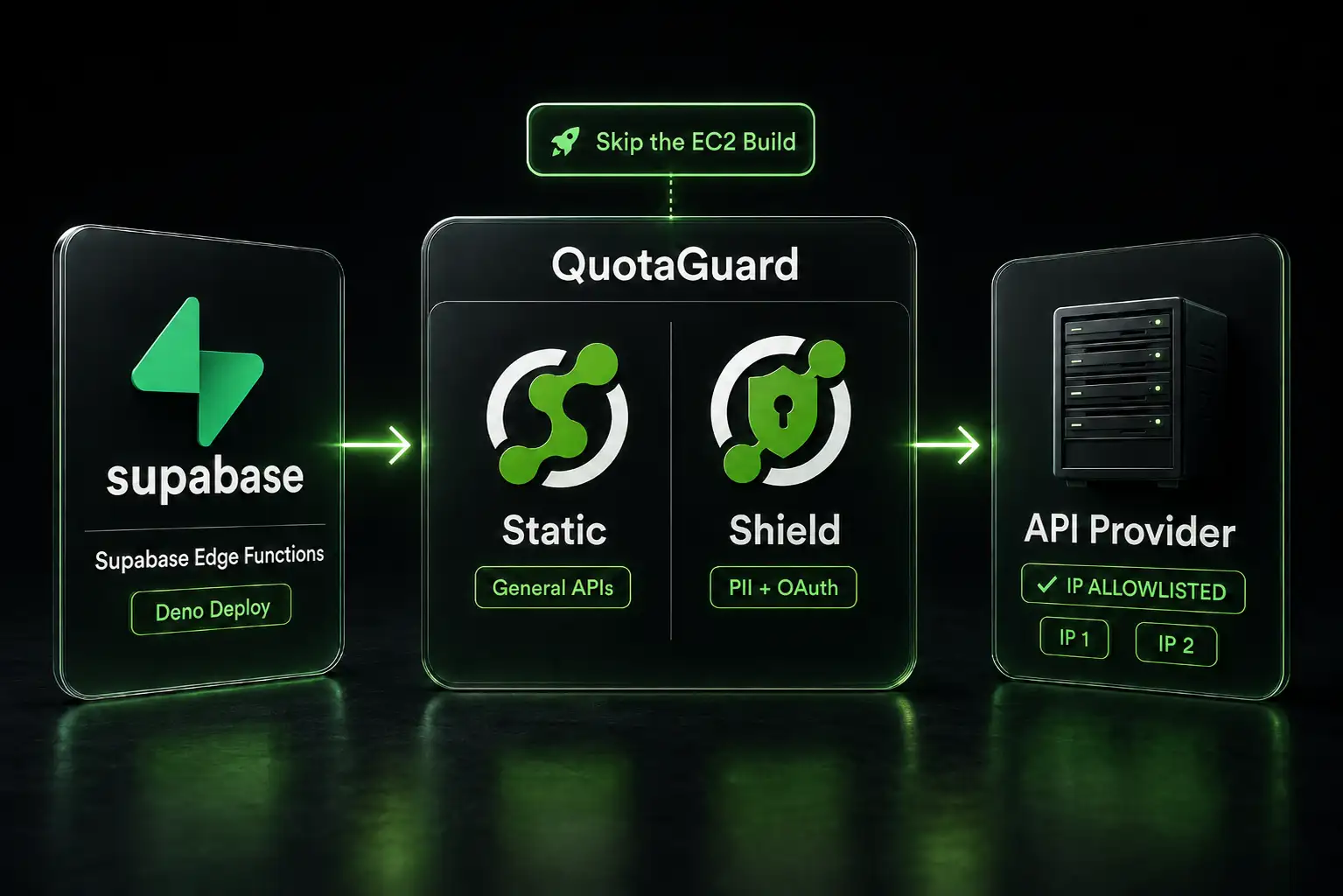


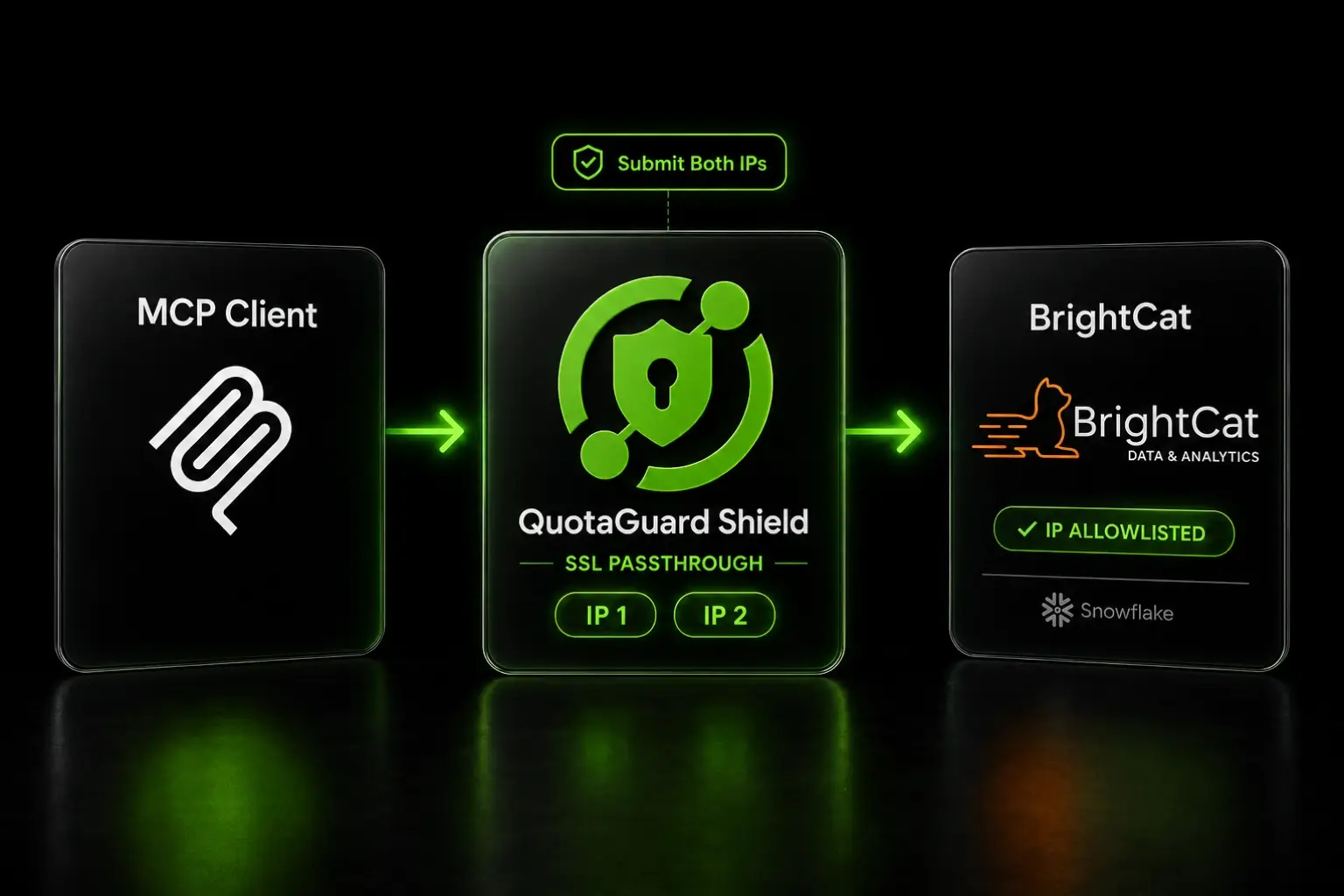

















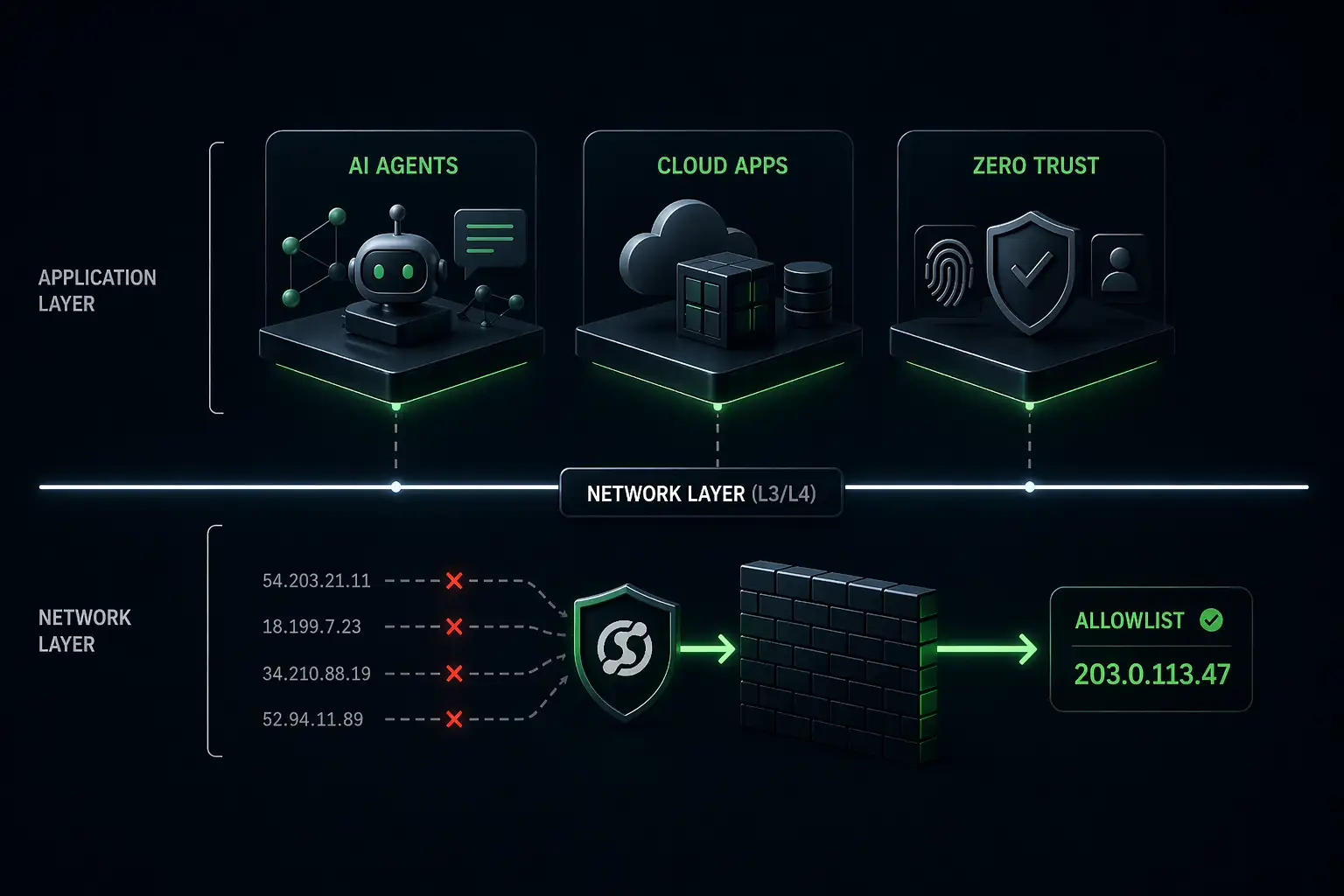


.webp)


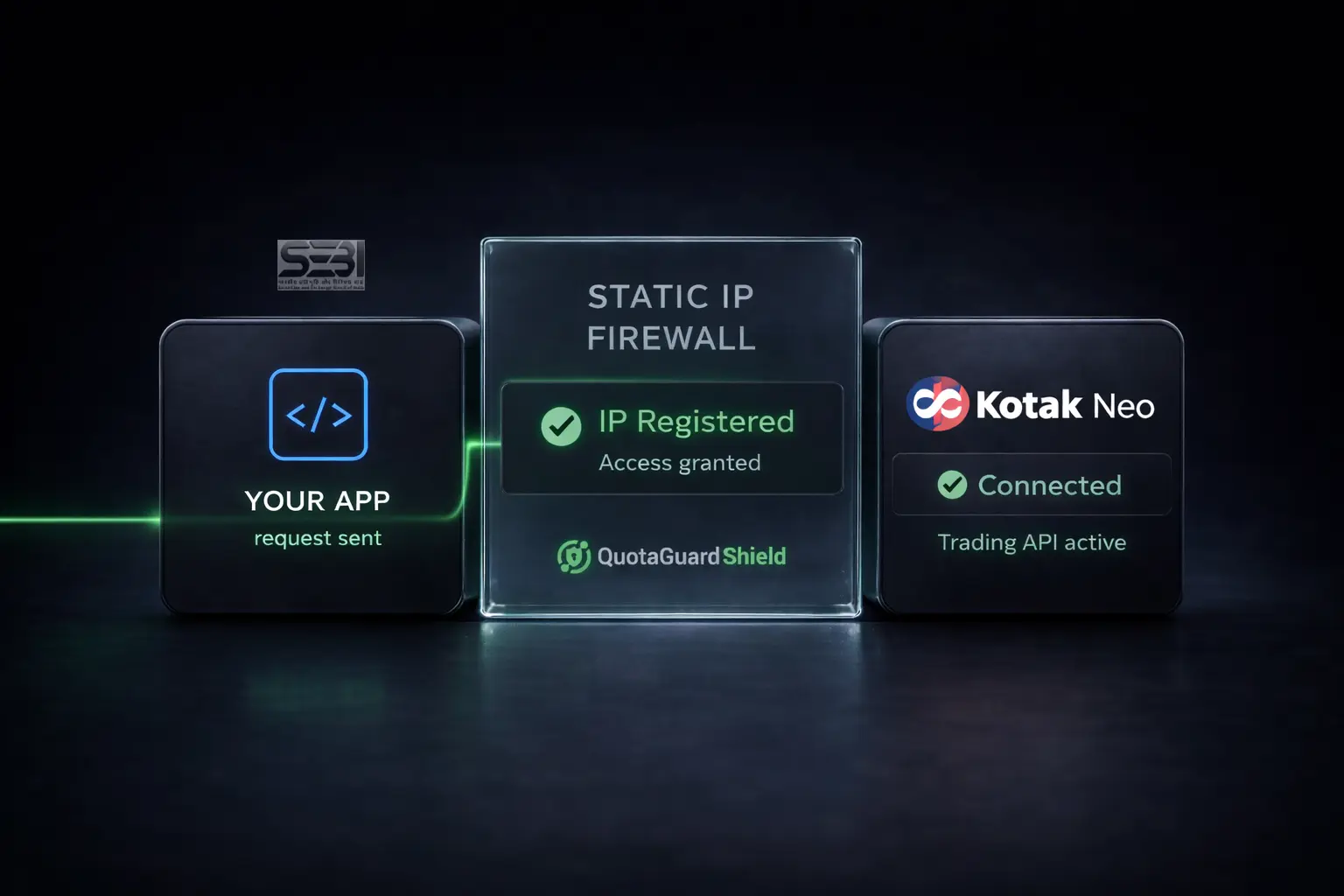
.webp)







.webp)


.webp)



.webp)


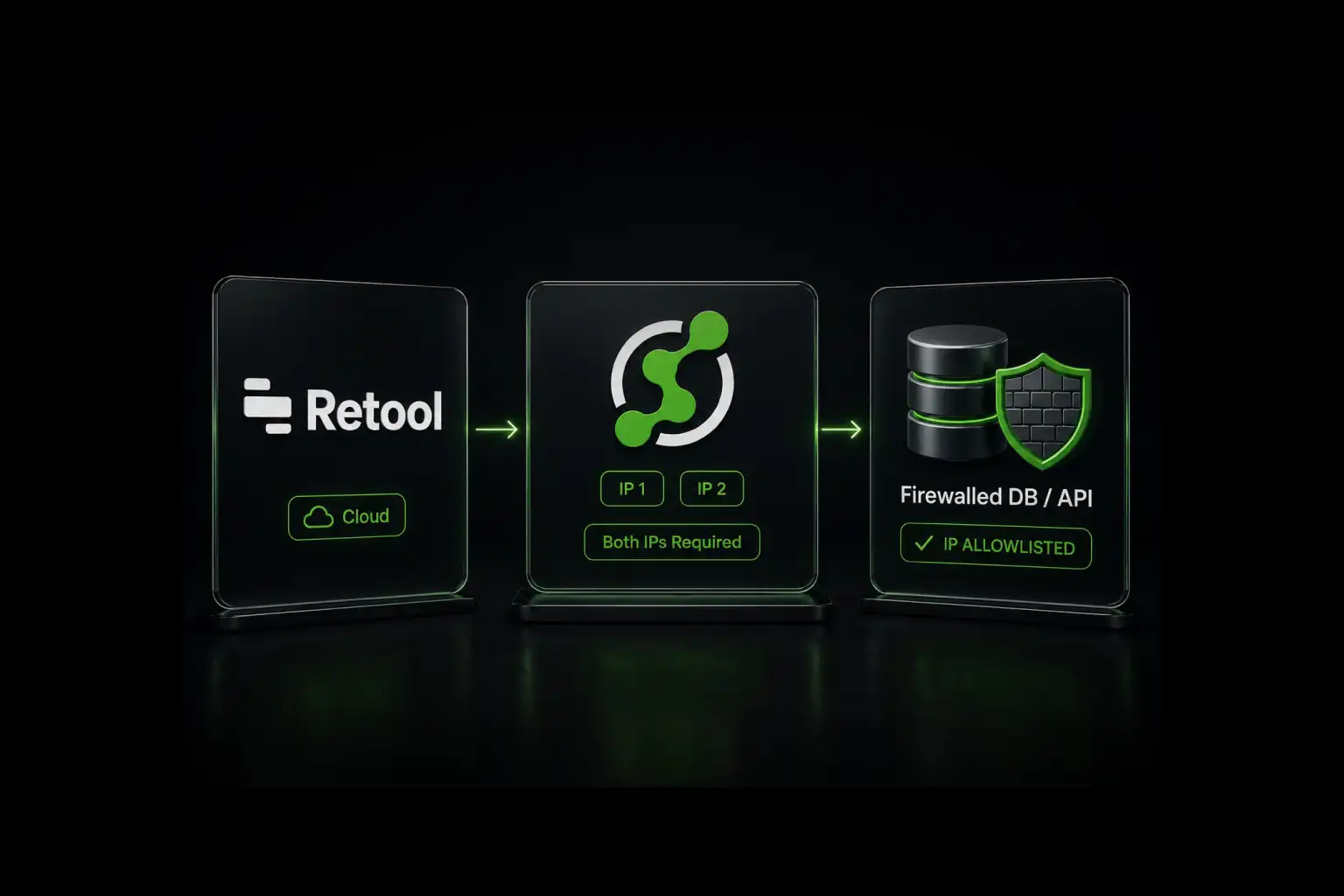

.%20Three%20Options%20Compared%20(1).webp)
.webp)
.webp)


.webp)
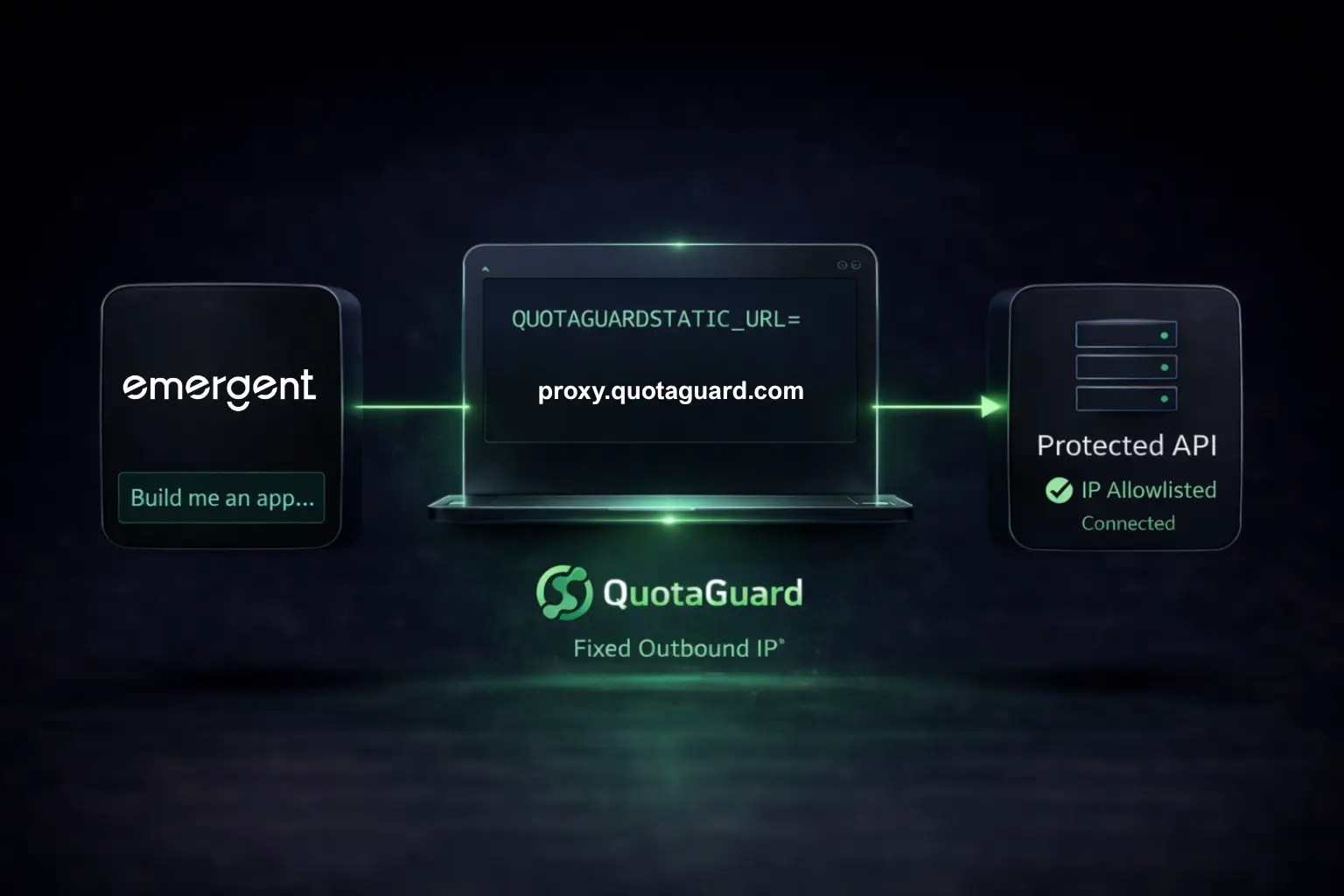








.webp)